
当AI编码后果擢升10倍,为何合座需求托福仅提速2-3倍?真相藏在被淡薄的审阅带宽与系统瓶颈中。本文机敏指出:AI期间的信得过限速点并非本领材干,而是古老的审阅体系、闭塞的系统架构与缺失的包袱包摄机制——这些恰正是产物司理最能发力的战场。

阿里本领最近有一篇著作,数据很扎心:深度使用AI的工程师,纯编码后果擢升了10倍,但端到端的需求托福后果只擢升了2到3倍。
许多东谈主看到这个数字会说:AI还不够熟识。
但若是你果然把ClaudeCode、Cursor、Manus这些用具用进泛泛责任,用到上瘾,你会发现一件反直观的事——限速的方位,根蒂不是AI材干。
行为产物司理,我想共享3件事:AI期间的确切瓶颈在那里,以及一个险些莫得东谈主在阐述究诘、但晨夕会爆的治理问题。

一、把产出换算成token,瓶颈就看了了了
传统帅悟里,”AI提效”的图景是这么的:工程师用AI写代码,速率变快,需求托福当然变快。
但若是你把东谈主和AI的产出皆换算成token速率来算计,会获取一个很不雷同的图景:
AI的写入速率,巧合是东谈主的10倍以上
AI的读取速率,更是东谈主的1000倍以上
ClaudeCode、OpenClaw、Manus这类用具,本色上作念了一件很粗浅的事:把权限和”手”(鼠标键盘的截止权)交给了AI,免却了用户把AI输出复制粘贴的中间方法。
然则,审阅莫得免却。
当AI的输出速率是东谈主的10倍时,东谈主的审阅带宽就成了整个责任流里最窄的方位。你不是在等AI写代码,你是在等我方看完AI写的代码。
这即是端到端后果只擢升2到3倍的信得过原因:AI的出产后果擢升了10倍,但东谈主的审阅后果莫得变。
问题不在AI,问题在于咱们还在用旧的审阅方式,对接新的出产速率。
二、审阅压力有莫得解法?有,但界限很通晓
率直讲,东谈主的审阅带宽是硬拘谨,莫得根蒂解法。
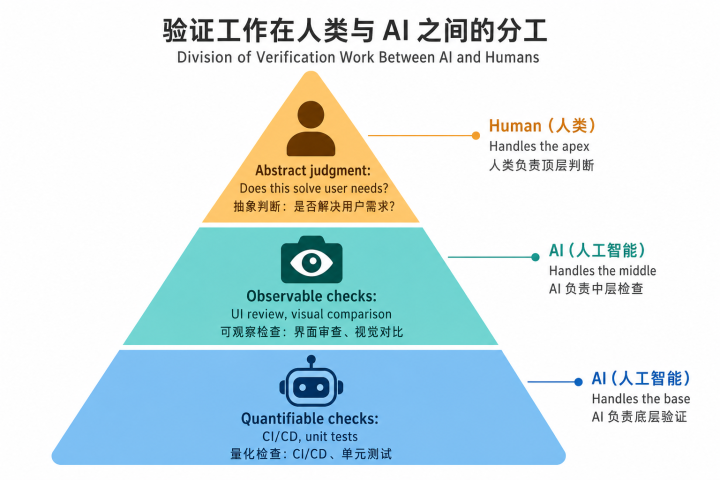
但有一个可行的分层策略:把”能量化的考证”外包给AI,把东谈主的元气心灵留给信得过详尽的判断。
第一层,可量化的考证——代码报错、单位测试、CI/CD活水线,这些皆不错交给考证Agent自动处理。不触及主不雅判断的,让机器来卡。
第二层,可不雅测的考证——UI走查、页濒临比、功能是否依期渲染,这类视觉考证不错用视觉MCP或Agent来完成。不需要东谈主眼一一阐发。
卸载这两层之后,东谈主负责的剩下什么?
“这个产物有莫得果然经管用户需求。”
这件事,到今天为止,莫得任何自动化有绸缪。你没法给AI一个尺度让它判断”用户会不会心爱这个”——这个判断背后需要对用户的共情、对场景的理会、对市集的直观,这些皆是AI替代不了的。
是以AI替代的是引申,不是产物判断。这是PM在AI期间确切的价值所在——但前提是你把前两层考证果然外包出去,而不是还在用东谈主眼逐行审查AI生成的代码。
三、信息瓶颈仍是上前移了,但大多数团队还不知谈
开云2026世界杯中国官网许晓斌在《AINative期间——研发组织何去何从》里建议过一个判断:AI进来之后最大的新瓶颈,不是AI材干不及,而是”系统的信息形态”——大量需求、文档、商定曲直结构化的,AI无法消化,东谈主反而酿成了在各个系统之间手动搬运数据的”东谈主肉中间件”。
这个判断在两年前是对的。
但刻下有一个变化值得防御:跟着主流AI的高下文窗口延长到1Mtoken,这个瓶颈仍是启动上前移了。
惟有给AI奢华的信息和权限,它透彻不错我方检索、我方理会、我方整合——根蒂不需要用户把问题翻译成AI能理会的形式。
但在许多团队里,K8凯发(中国)AI照旧用不上这个材干。原因不是AI不够机灵,是系统莫得对AI洞开接口:数据库莫得权限、运维系统莫得API、留传系统无法对接。
于是出现了一个跋扈的场景:职工从业务系统手动导出数据,复制粘贴给AI处理,再把AI的输出搬回系统——东谈主在演出系统和AI之间的中间件。
今活泼正的瓶颈,不是”如何写更好的prompt”,而是“如何让AI径直侦察你的系统”。这是一个系统接口化的问题,是架构问题,亦然数据安全战略的问题。
这件事,是PM能推进的,也应该推进的。花期间优化prompt,不如花期间推进IT和安全团队给AI开一个持重的数据侦察通谈。后者的复利,远浩大于前者。
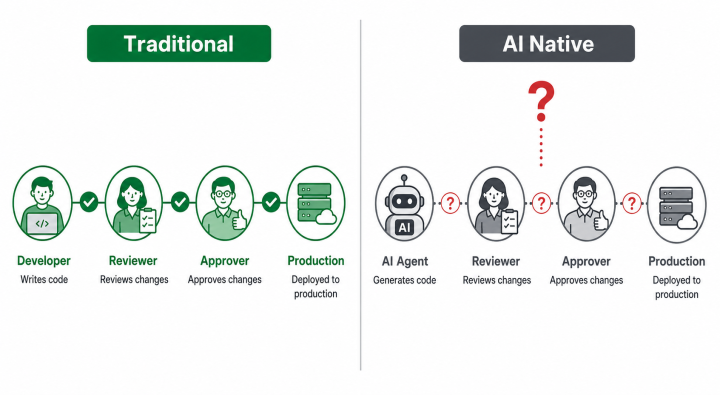
四、最大的盲区:AI写的代码,出了问题谁来负责?
这是产物司理圈究诘AI提效时,被说得最少、但可能最值得阐述对待的一个问题。
履行仍是走到了这里:ClaudeCode的大量更新,绝顶比例是由AI写出来的,东谈主只作念review,甚而是AIreviewAI。AI写代码的材干,今天仍是进步了市集上大多数的低级和中级斥地者。
然后呢?
然后莫得东谈主知谈出了问题该找谁。
在传统研发体系里,代码包摄是通晓的:谁写的、谁review的、谁approve的,出了线上问题,包袱链条明赫然白。这条链条不仅仅为了追责,更是为了让整个团队有能源去阐述对待我方的输出质地。
当AI成为主要的代码出产者,这条链条断了。
莫得东谈主信得过”领有”这段代码——AI莫得包袱感,review它的工程师也莫得和亲手写代码等价的ownership感。Commit记载里写的是谁的名字,但判断和产出是AI的。
这不是本领问题,是组织治理问题。而刻下险些莫得公司有齐全的应付有绸缪。
这个问题会在那里爆发?可能是一次线上故障,可能是一次安全缝隙,可能是一个暗暗上线的功能没东谈主发现存问题。到阿谁时候,才会有东谈主阐述启动念念考:谁来对AI的输出负责。
产物司理不错提前想这件事,并且是最有资历推进这件事的脚色:
谁来界说”AI参与度进步若干比例时,验收尺度需要治疗”?
谁来推进建立AI代码的参与度记载和可溯源性机制?
当AI写的代码出了用户投诉,PM应该如何复盘?
这些问题莫得现成谜底,但提前想了了的团队,会比被迫恭候爆发的团队,多出一个齐全迭代周期的应付空间。
想了了限速的方位,比换更好的用具更遑急
回到阿谁数字:纯编码后果10倍,端到端后果2到3倍。
差距不来自AI不够强。差距来自:咱们还没想了了限速的方位在那里。
用token速率的视角重新看我方的责任,你会发现:
AI不需要你帮它翻译需求,它需要的是系统接口
AI不需要你教它写代码,它需要的是量化的考证体系
AI写出的代码不需要你逐行审查,它需要的是通晓的包袱包摄机制
这三件事,刚巧皆是产物司理能推进、也应该推进的。
AI期间PM的护城河,不在”会用若干用具”,在于能看了了系统性的瓶颈在那里,然后推进经管它。
引申后果的10倍,是AI的礼物。端到端后果的剩余差距,是留给看了了瓶颈的东谈主去填的空间。
本文不雅点来自对AI用具的泛泛使用实践K8凯发官方网站,以及许晓斌《AINative期间——研发组织何去何从》的深度启发。